In this post, we show the demo of EAD-VC.
Model Architecture
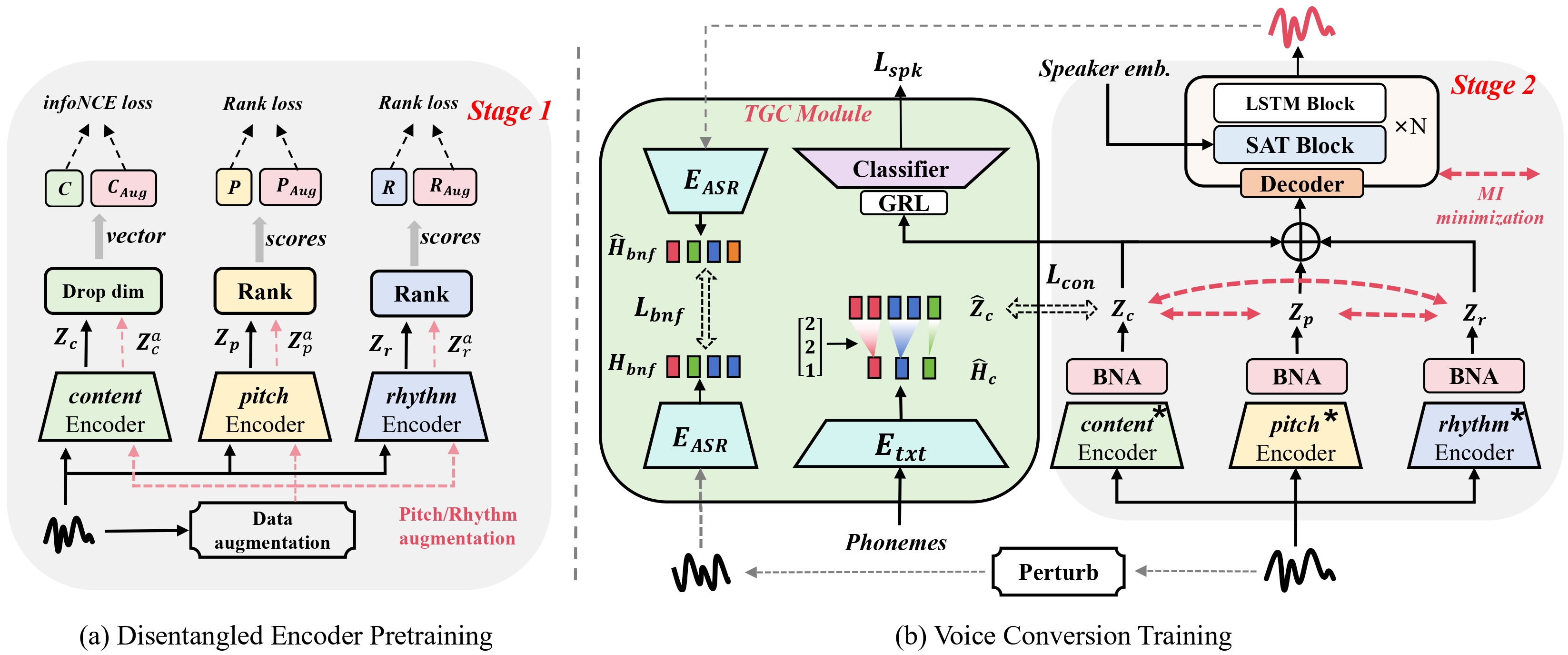
Figure.1 The architecture of the EAD-VC.
Experiment
Results
In order to evaluate and show the performance of our model, we list the four Tables to respective show the four Female-to-Male conversion (F2M), Male-to-Female conversion (M2F), One-Shot voice conversion (Timbre Conversion and Not Only Timbre Conversion).
| ID | Ground Truth | Adain-VC | SpeechFlow | Liu et al. | VQMIVC | EAD-VC |
|---|---|---|---|---|---|---|
| Sample 1 | ||||||
| Sample 2 | ||||||
| Sample 3 |
| ID | Ground Truth | Adain-VC | SpeechFlow | Liu et al. | VQMIVC | EAD-VC |
|---|---|---|---|---|---|---|
| Sample 1 | ||||||
| Sample 2 | ||||||
| Sample 3 |
| Text | Reference Timbre | Adain-VC | SpeechFlow | Liu et al. | VQMIVC | EAD-VC |
|---|---|---|---|---|---|---|
| That's no bad thing. | ||||||
| I love the lab of Large Audio Model. |
| Type | Pitch | Rhythm | Timbre | Pitch+Rhythm | Pitch+Timbre | Rhythm+Timbre | Pitch+Rhythm+Timbre |
|---|---|---|---|---|---|---|---|
| Liu et al. | |||||||
| EAD-VC |